发布时间:
网络爬虫的论文参考文献
python爬虫有哪些书?下面给大家介绍6本有关爬虫的书:
更多Python书籍推荐,可以参考这篇文章:《想学python看哪些书》
1.Python网络爬虫实战
本书从Python基础开始,逐步过渡到网络爬虫,贴近实际,根据不合需求选取不合的爬虫,有针对性地讲解了几种Python网络爬虫,所有案例源码均以上传网盘供读者使用,很是适合Python网络爬虫初学者使用。
相关推荐:《Python教程》
2.精通Python网络爬虫:核心技术、框架与项目实战
这本书代码全是基于Python3,本书基于Python从零基础开始,逐渐深入,再到爬虫框架到反爬到项目拭魅战,帮忙读者构建完整的知识系统,很是适合小白和刚接触爬虫的读者。
3.Python爬虫开发与项目实战
本书从爬虫涉及的多线程,多进程讲起,然后介绍web前真个基础知识,再到数据存储,网络协议,最后拭魅战项目,完全专注于Python爬虫,比较适合想要进阶Python爬虫的朋友。
4.用Python写网络爬虫
本书基础笼盖很全,把写一个爬虫所需的各个方面都写到,由于代码案例比较底层,所以适合有一定Python基础的小伙伴。
5.Python网络数据收集
作者是此行达人,代码优美简洁,运用年夜量递归算法和正则表达式,本书很好的利用Python完成从数据爬起到数据清洗整个流程的时间过程,更为难得的是用python3进行工程实践,而不只是讲解语法。
6.精通Scrapy网络爬虫
本书通过案例、源码,从零基础、逐步由浅入深进行详细讲解Python爬虫框架Scrapy,使读者能够对Scrapy框架有个清晰的认知,适用于有Python语言基础的读者。
做爬虫,特别是python写说容易挺容易,说难也挺难的,举个栗子 简单的:将上面的所有代码爬下来写个for循环,调用urllib2的几个函数就成了,基本10行到20行以内的代码难度0情景:1.网站服务器很卡,有些页面打不开,urlopen直接就无限卡死在了某些页面上(2.6以后urlopen有了timeout)2.爬下来的网站出现乱码,你得分析网页的编码3.网页用了gzip压缩,你是要在header里面约定好默认不压缩还是页面下载完毕后自己解压4.你的爬虫太快了,被服务器要求停下来喝口茶5.服务器不喜欢被爬虫爬,会对对header头部浏览器信息进行分析,如何伪造6.爬虫整体的设计,用bfs爬还是dfs爬7.如何用有效的数据结构储存url使得爬过的页面不被重复爬到8.比如1024之类的网站(逃,你得登录后才能爬到它的内容,如何获取cookies以上问题都是写爬虫很常见的,由于python强大的库,略微加了一些代码而已难度1情景:1.还是cookies问题,网站肯定会有一个地方是log out,爬虫爬的过程中怎样避免爬到各种Log out导致session失效2.如果有验证码才能爬到的地方,如何绕开或者识别验证码3.嫌速度太慢,开50个线程一起爬网站数据难度2情景:1.对于复杂的页面,如何有效的提取它的链接,需要对正则表达式非常熟练2.有些标签是用Js动态生成的,js本身可以是加密的,甚至奇葩一点是jsfuck,如何爬到这些难度3总之爬虫最重要的还是模拟浏览器的行为,具体程序有多复杂,由你想实现的功能和被爬的网站本身所决定爬虫写得不多,暂时能想到的就这么多,欢迎补充
网络爬虫论文相关文献
网站设计参考文献
网站设计要能充分吸引访问者的注意力,让访问者产生视觉上的愉悦感。因此在网页创作的时候就必须将网站的整体设计与网页设计的相关原理紧密结合起来。下面是我整理的网站设计参考文献,欢迎阅读与收藏。
网站设计参考文献
现在随着互联网的越渐强大,网站的建设就需要融入更多的功能、更丰富的内容和更美观更人性化的界面设计.如果一个网站既没有美观大方的界面设计也没有能够留住用户而设计的易懂易操作的功能,就失去了存在的意义.下面是我整理的网站设计参考文献,供大家借鉴参考.
[1]龚晓丽,田倍齐,高媛,何云,李宜珈.基于微信公众平台的固原气象微网站的设计与实现[J].农业与技术,2020,40(08):106—107.
[2]邢彤彤,覃蕊,高峰.基于PHP+MySQL技术的农家乐推广网络系统开发与实现[J].计算机产品与流通,2020(05):52.
[3]乐蓓.高性能电子商务网站前端设计理念研究[J].计算机产品与流通,2020(05):95.
[4]董辉,韩林贝,董浩,袁登鹏,李华昌.基于Web的手套机工业物联网平台设计与开发[J].计算机测量与控制,2020,28(04):200—204.
[5]路志红.电力网络视频网站版权风险管理信息系统的设计[J].变压器,2020,57(04):93.
[6]杨晶晶.网站管理系统中数据库设计的应用[J].福建茶叶,2020,42(04):39.
[7]张欢,姜在新.基于不同人群的农产品电商界面设计研究[J].轻纺工业与技术,2020,49(04):114—115.
[8]杨毅,林圣基,周元春,陈建国.基于智能手机与WEB平台的微课移动教学系统设计与实践[J].自动化技术与应用,2020,39(04):182—185.
[9]柴畅.跨境电商平台中美购物网站店铺主页的跨文化比较[J].电子商务,2020(04):33—34+36.
[10]陈猛.基于Java的购物网站设计与开发[J].农家参谋,2020(08):200.
[11]袁莹静,陈婷,陈龙,周芷仪,谢鹏辉.基于Web的二手车交易系统的设计与实现[J].软件,2020,41(04):195—199.
[12]周宇轩,朱科旭,杨知涵,唐诗钰,褚永彬.基于HTML5的“慢游”旅游Web App设计与实现[J].电脑与信息技术,2020,28(02):47—50.
[13]王昭.基于用户体验的中国扇文化推广类网站的设计研究——以“京扇子”品牌官方网站设计为例[J].设计,2020,33(07):28—31.
[14]肖文娟,王加胜.基于Vue和Spring Boot的校园记录管理Web App的设计与实现[J].计算机应用与软件,2020,37(04):25—30+88.
[15]邬洪波.基于PHP技术的视频点播网站设计[J].集成电路应用,2020,37(04):68—69.
[16]陈红梅,李柯瑶.“考研派”考研综合辅导网站设计与实现[J].中外企业家,2020(11):215.
[17]张德宝.网页欣赏精品分析教学平台的设计[J].黑龙江科学,2020,11(07):98—99.
[18]王建,罗政,张希,张梦琪,张科,马文成.Web项目前后端分离的设计与实现[J].软件工程,2020,23(04):22—24.
[19]王小飞,韩继凯,王元鑫,袁涛.基于Web标准的虚拟实验教学平台的研究与设计[J].办公自动化,2020,25(07):49—52.
[20]曹巍,尤晓东.《网页设计》课程的综合实验设计[J].教育教学论坛,2020(14):114—116.
[21]沈旭,柯晴,王新政.移动应用程序开发精品课程网站研究与设计[J].软件工程,2020,23(01):54—58.
[22]马宁,陈曦,张李铭.基于Selenium与Openpyxl的Web脚本自动化设计研究[J].电脑知识与技术,2020,16(01):51—53+70.
[23]牛慧清.网站建设的平面设计技术研究[J].科技资讯,2020,18(01):15+17.
[24]徐文君,袁占良.Web室内地图导览系统设计与实现[J].科技通报,2019,35(12):37—40+45.
[25]潘红玉,刘博夫.高校门户网站响应式设计方法与实践[J].科教文汇(下旬刊),2019(12):120—121.
[26]林婷婷,曲洪建.服装网站设计对购买意愿的影响研究[J].上海工程技术大学学报,2019,33(04):392—398.
[27]徐刚,翟梦娇.基于SSM的美容资讯商务网站的设计与实现[J].商丘职业技术学院学报,2019,18(06):65—71.
[28]曹利.基于Bootstrap旅游网站设计与实现[J].太原师范学院学报(自然科学版),2019,18(04):65—67.
[29]潘蕊.SSH框架的Web网站设计与实现研究[J].成才之路,2019(36):58—59.
[30]张君,阮庆玲,康艳梅,郑纯静,彭俊超,程礼童.宠物殡葬服务网站的设计开发探讨[J].畜牧兽医科技信息,2019(12):6—7.
[31]计大威.基于WEB系统与J2EE开发技术的财务凭证管理系统设计与实现[J].自动化技术与应用,2019,38(12):160—163.
[32]张贵强,王美玲.基于NodeJS的企业网站的设计与实现[J].信息技术与信息化,2019(12):58—60.
[33]毛捷磊.新时期网页设计中计算机图像处理技术应用分析[J].数字技术与应用,2019,37(12):65—66.
[34]李昂,姚新改,梁星,董志国.基于Pro/Web.Link的冷等静压机绕丝缸在线设计[J/OL].机电工程,2019(12):1290—1293+1308[2020—05—14].
[35]蔡长征.数据库设计在网站开发中的应用研究[J].科技风,2019(35):80.
[36]李昂,姚新改,梁星,董志国.基于Pro/Web.Link的冷等静压机绕丝缸在线设计[J].机电工程,2019,36(12):1290—1293+1308.
[37]唐滔.基于Web技术的农产品网站设计与实现[J].电脑编程技巧与维护,2019(12):18—20.
[38]何明慧,刘云鹏.高校“导学互动”模式下《网页设计与制作》课程教学改革实践[J].计算机工程与科学,2019,41(S1):50—54.
[39]李亚男.计算机网页设计中图像处理技术的应用[J].无线互联科技,2019,16(23):136—137.
[40]熊建宇.文学网站的设计与开发[J].技术与市场,2019,26(12):89—90.
[41]韦玉辉,苏兆伟,潘美林.基于Web页面的服装个性化定制系统设计与实现[J/OL].浙江理工大学学报(自然科学版):1—6[2020—05—14].
[42]孙炯宁.高校求职招聘网站系统的设计与实现[J].数字技术与应用,2019,37(11):157+159.
[43]罗路腾,王贵鑫.基于Springboot的博客网站的设计与实现[J].科学技术创新,2019(33):64—66.
[44]刘雅慧.基于Struts框架的考研资讯平台的设计与开发[J].现代信息科技,2019,3(22):22—24.
[45]侯冬青,宫育全,朱明红.基于“引导—发现”策略的“走近细胞”专题网站的设计与开发[J].信息技术与信息化,2019(11):133—136.
[46]侯冬青,李敏,罗玉洁.“幼儿学英语”专题网站的设计与开发[J].信息技术与信息化,2019(11):154—157.
[47]丁浩.基于MVC模式的购物网站设计研究与实现[J].电脑知识与技术,2019,15(33):27—29.
[48]廖妍.网页设计中计算机的图像处理[J].数字技术与应用,2019,37(11):67—68.
[49]黄涓,鲍正德,李晨曦.旅游网站的建构与设计——以国内六大旅游网站为例[J].信息与电脑(理论版),2019,31(22):52—54.
[50]周橙旻,于梦楠.基于用户体验的家具展示类网站设计研究[J].包装工程,2019,40(22):181—189.
[51]杜鹏辉,仇继扬,彭书涛,柴沣伟,刘意先.基于Scrapy的网络爬虫的设计与实现[J].电子设计工程,2019,27(22):120—123+132.
[52]夏天,张宁,王大众,何俊花,沈瑶,黄晓瑞.Web 3.0时代的档案网站评价指标体系构建[J].档案学通讯,2019(06):64—71.
[53]赵富强,罗伍周,朱小波.基于Android和Web的通用航空业务管理系统设计与实现[J].现代计算机,2019(32):65—72.
[54]赵国文.基于Web的智能家居远程控制系统设计与实现[J].花炮科技与市场,2019(04):235+242.
[55]戴宏明,戴宏亮.基于HTML5大型营销型网站设计研究[J].软件,2019,40(11):57—61.
[56]张辉,李子源,张阳.博物馆微环境监控系统Web端软件设计[J].计算机应用与软件,2019,36(11):11—13+46.
[57]高波,刘琳琳.基于站群系统管理的图书馆网站设计与开发[J].企业科技与发展,2019(11):48—49.
[58]邱俊豪,朱文列,李健,纪毓新.基于Java Web的“共享南国”食堂点餐系统的设计与实现[J].现代信息科技,2019,3(21):62—64.
[59]庄丽君.网页设计中计算机图像处理技术的应用[J].无线互联科技,2019,16(21):21—22.
[60]卜同,赵巍.基于外籍游客视角的智能导游系统网站的设计与研究——以沈阳景区为例[J].现代信息科技,2019,3(21):83—84.
[61]王美芝,支学超,刘财辉.基于Python的多线程聚焦网络爬虫设计与实现[J].赣南师范大学学报,2019,40(06):35—38.
[62]孙荣明.以Web与数据库算法为载体的软件应用设计分析[J].信息与电脑(理论版),2019,31(21):46—47.
[63]杨嘉诚,柯海丰.基于HTML5和JavaScript的信息学学习网站的设计与实现[J].计算机时代,2019(11):32—34+37.
[64]刘桃丽,曾志超.MVC架构下网站的设计与实现[J].计算机技术与发展,2020,30(02):188—191.
[65]刘剑桥,孙刚,魏梦雪,曹飞虎.摩登农场网站的设计与实现[J].电脑知识与技术,2019,15(31):35—36+44.
[66]刘珍,方明.基于Spark Sreaming网站流量实时分析系统的设计与实现[J].智能计算机与应用,2019,9(06):201—205.
[67]袁智,李樾,张正伟.基于HTML5的跨平台家具网站设计与实现[J].信息记录材料,2019,20(11):177—178.
[68]李泗兰,郭雅.视觉空间元素在网页设计中的应用研究[J].电脑知识与技术,2019,15(29):212—214.
[69]朱育林.基于Web前端开发的公司网站设计[J].河南科技,2019(28):36—38.
[70]史雪雪,刘清惓,浦玮,王定奥.强制通风温度传感器辐射误差修正与网站设计[J].现代电子技术,2019,42(19):149—153.
[71]朱健.基于Web技术的PSX800后台系统的设计与实现[J].计算机时代,2019(10):47—49+53.
[72]王勇,卢磊.基于网络爬虫的上市公司交易数据共享平台设计[J].价值工程,2019,38(27):267—269.
[73]张宏.网页设计中的图形图像处理技巧探索[J].信息与电脑(理论版),2019,31(18):154—156.
[74]盛凯,毛红霞.基于新浪微博网站的数据采集的设计与实现[J].信息与电脑(理论版),2019,31(18):92—93+98.
[75]黄文灿.基于Java Web的旅游服务系统设计研究[J].数字技术与应用,2019,37(09):156—157.
[76]孔波,邹有,卢红兵,杨华武,庹苏行.基于Web的色质数据解析平台设计与开发[J].计算机技术与发展,2019,29(12):198—204.
[77]闫朝阳.基于Web的大数据分析平台交互设计研究[J].设计,2019,32(17):94—97.
[78]胡念祖,林晓焕,肖新帅.基于嵌入式Web服务器的远程温度采集系统设计[J].舰船电子工程,2019,39(09):113—117+182.
[79]谭卫,阳晓霞.基于移动Web技术的高校思想品德教育工作评价系统设计与研究[J].信息与电脑(理论版),2019(15):101—104.
[80]宋丽芳.网站建设中网页设计的安全缺陷及对策分析[J].信息通信,2019(08):113—114.
[81]吴城.跨境电商网站系统的设计与分析[J].商场现代化,2019(15):37—38.
[82]蔡振海,张静.基于python的网络爬虫系统的设计与实现[J].电脑知识与技术,2019,15(23):36—37.
[83]黄绍涵.“HZD”校友圈社交网站设计与开发研究——就业模块设计[J].电声技术,2019,43(08):29—32.
[84]李翔宇.基于Web前端开发技术的儿童教育网站设计与实现[J].中国新通信,2019,21(15):196.
[85]曾婷,凌财进.基于HTML5的计算机一级考试模拟Web APP的设计与实现[J].办公自动化,2019,24(15):60—62.
[86]王立强.HTML5:电商网站设计与实现[J].营销界,2019(30):152—157.
[87]黄安.基于PHP+Mysql技术的网站设计与实现——以美食网站系统的设计为例[J].轻纺工业与技术,2019,48(07):168—170.
[88]张欢.服务类网站设计与经营模式的实例研究[J].科技经济导刊,2019,27(21):207+197.
[89]王瑞,徐方晨.开放共享实验室的Web平台设计与实现[J].工业控制计算机,2019,32(07):120—122.
[90]苏思雨,陈汝倩.长白山体验式旅游日文网站的设计与建设[J].数字技术与应用,2019,37(07):139—140.
[91]高宁婧.小说付费阅读类型网站用户体验的问题与对策[J].大众文艺,2019(10):265—266.
[92]于欢,李梅.医科类高校图书馆网站运行及界面设计情况探究[J].科学技术创新,2019(15):84—85.
[93]高香,宋敦江,梅新.基于Web的地形匹配系统设计与开发[J].计算机测量与控制,2019,27(05):226—230+235.
[94]冯思度,杨健叶,韩煦.基于医疗信息的网络爬虫系统的研究与设计[J].现代信息科技,2019,3(10):23—25.
[95]刘纯,赵茂林.数字媒体时代多媒体网站页面设计中的美学因素研究[J].中外企业家,2019(15):52.
[96]曾棕根.ThinkPHP模式下网页自动认证机制的设计[J].福建电脑,2019,35(05):25—28.
[97]吴恒,戴晓虎.基于Web的家庭乐园分享平台的设计与实现[J].现代信息科技,2019,3(10):86—87+91.
[98]隋欣,赵玲,张欣,王东磊,尚绪豪.基于PHP的“接钥匙”装修网站的设计与实现[J].电脑知识与技术,2019,15(15):92—93.
[99]姚晓婷.用户体验视角下的产品网页视觉传达设计——以电子产品为例[J].黑河学院学报,2019,10(05):173—175.
[100]王强,张虎,宋冰严,刘星星,程龙飞.基于Java Web的网上医药商城的设计与实现[J].无线互联科技,2019,16(10):28—29+32.
[101]梅元昭.基于Jquery课程网站的设计[J].无线互联科技,2019,16(10):39—41.
[102]郑洲.一种基于物联网的智能家居网站设计探讨[J].计算机产品与流通,2019(06):123.
[103]周伟,左右飞.基于Bootstrap的校园招聘网站的设计与实现[J].信息技术,2019,43(05):29—32.
[104]杨正午.基于WEB前端开发技术的网站设计——以连锁超市商品销售管理系统为例[J].山西科技,2019,34(03):51—53+57.
[105]刘玉洁,韩松歧.易果生鲜网站首页设计研究[J].电子商务,2019(05):31+76.
拓展资料:
网站介绍
简单来说,网站设计的目的就是产生网站。简单的信息如文字,图片(GIFs, JPEGs,PNGs)和表格,都可以通过使超言、可扩展超文本标记语言等标示语言放置到网站页面上。而更复杂的信息如矢量图形、动画、视频、声频等多媒体档案则需要插件程序来运行,同样地它们亦需要标示语言移植在网站内。网页设计是设计过程的前端(客户端)的设计通常用于描述一个网站,包括写标记,但是这是一个灰色地带,因为这还覆盖了网络的发展。网页设计师预计将有意识的可用性,如果他们的作用,需要创建标记,那么它们也有望成为最新的网页易读性指引。网站设计(Web Design),网站设计是一个把软件需求转换成用软件网站表示的过程,就是指在因特网上,根据一定的规则,使用Dreamweaver、photoshop等工具制作的用于展示特定内容的相关网页的集合。简单地说,网站是一种通讯工具,就像布告栏一样,人们可以通过网站来发布自己想要公开的资讯(信息),或者利用网站来提供相关的网络服务(网络服务)。人们可以通过网页浏览器来访问网站,获取自己需要的资讯(信息)或者享受网络服务。网站它是由域名(俗称网址),网站源程序和网站空间三部分构成。其中域名它是类似于互联网上的门牌号码,是用于识别和定位互联网上计算机的层次结构式字符标识,与该计算机的互联网协议(IP)地址相对应。而网站设计是设计师通过像Frontpage或Dreamweaver等工具来对网站进行编辑的!
设计原则
自适应网页设计也称为 响应性的Web设计 -设计网页,提供一个很好的感知上的各种设备连接到互联网。
自适应网络设计的目的是为不同设备的多功能网站。网站是为了更方便地查看不同的分辨率和格式的设备,技术,自适应网页设计没有为特定类型的设备创建一个单独的版本的网站。一个网站可能无法在您的手机,平板电脑,笔记本电脑和电视上网,要满足全范围的设备最佳显示。
设计版权
可选择融合和集成各种数字版权技术和权威时间戳公证处公证邮箱等可信第三方群支撑的'支持的大众版权认证保护平台进行网站设计版权自主存证和首次发布智能认证,取得作品归属权初步证明,需要时,通过司法鉴定,增强证据的法律效率是核心保障
建站过程
准备内容
在域名注册查询网址之前就应该先搜集至少「一百页」的内容,这些内容必须是有价值的、不违反著作权的内容。
网址
想个比较有意义,好记的网址。
网页设计制作
对搜索引擎来说,他们无法检索到网站里的flash、java applet和javascript,也无法检索到你图档里写的字,所以在网站设计上,只要尽量简洁有力,让内容可以好好的呈现,就是一个成功的seo网站页面。页要尽量符合w3c的标准。
每页档案大小
建议每个网页尽量在15k以下,如果可以缩减到12k,甚至10k那就更好,但是不能在5k以下,以免影响内容的完整。其实我们都知道,搜索引擎最佳化的目的,实际上是为了使用者,而不是为了搜索引擎本身。
内容
每天建立一个500~1000字的网页,当然这个网页里面必须包含你重要的关键字,如果想不出关键字来的话,可以使用Yahoo的关键字建议工具
关键字密度
拿出你的关键字,在下列六个地方各使用一次:
标题;
meta标签;
网址;
粗体关键字 (就是写出你的关键字,然后把他加粗);
斜体关键字 (就是写出你的关键字,然后把他斜体);
页面上半部 (网页内容比较前面的地方,我是建议用个标题,像是h1)。
内部链接
内部链接就是在同一网站域名下的内容页面之间的互相链接(自己网站的内容链接到自己网站的内部页面,也称之为站内链接)。合理的网站内链接构造,能提高搜索引擎的收录与网站权重。你的网站里面可能有很多类的内容,请确定同类内容互相链接,而不同类内容千万不要互相链接。例如讲食品的页面请链接到讲水果的页面这样。
为什么要这样作呢?同类内容的内部链接可以让google的pagerank在你的网页里互相传递,如果你只对个别网页作最佳化,有可能会发生的情况是,网站里只有少数几个页面的排名可以往前,但是若是做好内部链接的话,可以让每个网页的排名都往前。
你想要五十个网页每天都可以带来一位访客,还是只有一个网页,每天带来五十位访客呢?前者还有机会可以努力,后者要再增加应该有其限度才对。
网站上线
最好不要用虚拟主机,若是能有自己的代管主机或者是固定ip位置就最好了。若是租用虚拟主机厂商的虚拟主机方案,你可能遇到的就是一台主机里面放上万个网站,尽管Yahoo和Google宣称,他们对待虚拟主机一视同仁,但是我还是担心要他们开始把同一主机ip数量加入排名公式的那天…
确认网站的每一页都可以被搜索引擎索引进去,网站里的链接要做好。另外呢,在网站还称不上是个「好网站」的时候,不要让网站上线,若是随便让你的烂网站进入搜索引擎,并且被打了低分之后,我想,要让分数上升似乎就不是那麼容易了。
接著,把自己加入到odp(open directory project),这是一个大家可以手动加入的目录索引,这样至少你的网站已经在一个索引里面了,接著,若是有钱的话,可以使用搜索引擎快速付费登录,这可以让你的网站在一定的时间内排名增加到前几名,若是没钱的话也没关系,慢慢等还是会被登录进去的。
送交搜索引擎
把你的网站登录好后,接著,就放著不管了。别忘了,这篇文章的目的是建立成功的网站,过程是一年,所以把网站送交登录之后,请耐心等待六个月。(最惨的情况下啦,不过一般来说,新网站最迟三~五个星期就会进入索引里面了)
网站推广
网站推广毋庸置疑任何一个想盈利的网站都无法回避付费推广服务,推广方面最主要的就是竞价排名。网站推广在建站之后是最重要的一步!
纪录与追踪
申请一个不错的网页计数器。
程序设计
网站设计包括前台用户视觉体验的设计和后台程序功能设计,两个方面都是非常重要的;视觉设计对于客户的阅读带来愉悦和信任,后台注重操作的方便行。
制作流程
以下是网站设计公司服务流程及图示,并对所需注意的有 关事项提供专业和详细的讲解。
1、需求-客户需求沟通分析 ;
2、签约-签署相关合同协议、客户支付预付款;
3、实施-网站页面设计、制作、程序开发;
4、验收-网站测试及验收;
5、维护-网站后期维护工作。
动态网站
网络技术日新月异,细心的网友会发现许多网页文件扩展名不再只是“.htm”,还有“.php”、“.asp”等,这些都是采用动态网页技术制作出来的。
早期的动态网页主要采用CGI技术,CGI即Common Gateway Interface(公用网关接口)。您可以使用不同的程序编写适合的CGI程序,如Visual Basic、Delphi或C/C++等。虽然CGI技术已经发展成熟而且功能强大,但由于编程困难、效率低下、修改复杂,所以有逐渐被新技术取代的趋势。
技术
PHP
PHP即Hypertext Preprocessor(超文本预处理器),它是当今Internet上最为火热的脚本语言,其语法借鉴了C、Java、PERL等语言,但只需要很少的编程知识你就能使用PHP建立一个真正交互的Web站点。
它与HTML语言具有非常好的兼容性,使用者可以直接在脚本代码中加入HTML标签,或者在HTML标签中加入脚本代码从而更好地实现页面控制。PHP提供了标准的数据库接口,数据库连接方便,兼容性强;扩展性强;可以进行面向对象编程。
ASP
ASP即Active Server Pages,它是微软开发的一种类似HTML(超文本标识语言)、Script(脚本)与CGI(公用网关接口)的结合体,它没有提供自己专门的编程语言,而是允许用户使用许多已有的脚本语言编写ASP的应用程序。ASP的程序编制比HTML更方便且更有灵活性。它是在Web服务器端运行,运行后再将运行结果以HTML格式传送至客户端的浏览器。ASP程序语言最大的不足就是安全性不够好。
ASP的最大好处是可以包含HTML标签,也可以直接存取数据库及使用无限扩充的ActiveX控件,因此在程序编制上要比HTML方便而且更富有灵活性。通过使用ASP的组件和对象技术,用户可以直接使用ActiveX控件,调用对象方法和属性,以简单的方式实现强大的交互功能。
但ASP技术也非完美无缺,由于它基本上是局限于微软的操作系统平台之上,主要工作环境是微软的IIS应用程序结构,又因ActiveX对象具有平台特性,所以ASP技术不能很容易地实现在跨平台的Web服务器上工作。
JSP
JSP 即Java Server Pages,它是由Sun Microsystem公司于1999年6月推出的新技术,是基于Java Servlet以及整个Java体系的Web开发技术。
JSP和ASP在技术方面有许多相似之处,不过两者来源于不同的技术规范组织,以至 ASP一般只应用于Windows NT/2000平台,而JSP则可以在85%以上的服务器上运行,而且基于JSP技术的应用程序比基于ASP的应用程序易于维护和管理,所以被许多人认为是未来最有发展前途的动态网站技术。
NET
NET是ASP的升级版,也是由微软开发,但是和ASP却有天壤之别。NET的版本有1.1、2.0、3.0、3.5、4.0。是网站动态编程语言里最好用的语言,不过易学难精。NET2.0开始,NET把前台代码和后台程序分为两个文件管理,使得NET表现和逻辑相分离。NET网站开发跟软件开发差不多。NET的网站是编译执行的,效率比ASP高很多。NET在功能性、安全性和面向对象方面都做的非常优秀,是非常不错的网站编程语言。
ASP、.NET、JSP和PHP的优点和缺点
ASP
优点:
无需编译
易于生成
独立于浏览器
面向对象
与任何ActiveX scripting 语言兼容
源程序码不会外漏
Python可以使用文本分析和统计方法来进行文献分析。以下是Python进行文献分析的一些方法:1. 使用Python的自然语言处理(NLP)库,如NLTK或spaCy,来对文献进行分词、命名实体识别、词性标注等操作,以便对文献进行语言统计分析。2. 可以使用Python的Pandas库来对文献进行数据处理和分析,将文献数据导入Pandas DataFrame中,并对其进行数据清洗、统计分析、可视化等操作。3. 使用Python的网络爬虫库,如Requests和BeautifulSoup,来爬取在线文献数据库或社交媒体平台上的相关文章,并通过数据挖掘和机器学习算法来发现其中的相关性和趋势。4. 通过使用Python的数据可视化库,如Matplotlib和Seaborn,来将分析结果可视化,便于更好地理解大量数据和引领后续工作。总之,Python提供了灵活和强大的工具集,结合适当的文献分析领域知识,可以快速、便捷地完成文献分析任务。 举例来说,一个研究人员想对某个领域的文献进行分析,探究其中的研究重点、热点和趋势。首先,研究人员需要获得相关的文献数据,可以通过在线文献数据库或者社交媒体平台来获得。接下来,研究人员可以使用Python的网络爬虫库,如Requests和BeautifulSoup,来爬取这些数据,并将其存储到Pandas DataFrame中进行清洗和分析。例如,可以对文献进行分词、命名实体识别等操作,以便发现其中的热点和重点。然后,研究人员可以使用Python的数据可视化库,如Matplotlib和Seaborn,来将分析结果可视化,例如使用词云图、词频图、关联图等方式展示文献中的关键词、主题和相关性,以便更好地理解和表达分析结果。通过以上的Python工具和方法,研究人员可以对大量文献数据进行深度挖掘和分析,在较短时间内获得比较完整和准确的结果,提升研究效率和成果。
爬虫论文的参考文献
不是所有爬行动物都会受温度影响,我找到一篇论文,你可以看看。作者:青青草链接:来源:知乎著作权归作者所有,转载请联系作者获得授权。这个问题,或许下面这篇文章号称是拿到了进化生物学“圣杯”的文章能解答你的一点疑惑~目前的假设理论(瞎扯)很多,靠谱的实验不多,很大局限于鳄鱼、乌龟这些家伙的生活周期都巨长(跑野外伤不起啊,生物农工的悲惨生活,我会随便乱说吗,何况这些家伙的生活周期巨长啊~)比较有名的理论是:Charnov–Bull model,这个模型认为温度性别决定(Temperature-dependent sex determination,TSD)能够最大的增加种群的适应度.但是这个理论已知没有人能够证明,甚至被称为进化生物学里面的"圣杯".在08年的时候,D. A. Warner和R. Shine在nature上发表了他们在蜥蜴Jacky dragon (外国人貌似对“龙”一点概念都没有)上的研究成果。具体是这么做的:已知该蜥蜴在23~26度、30~33度下能够发育成雌性,而在这之间的温度则发育成雄性。并且该蜥蜴的温度调控机制由一种非醛固酮芳香酶调控,使用该酶的抑制剂能很精确控制蜥蜴的性别分化。由于这种蜥蜴的生活周期一般只有4年(是够短命的啊),他们能够计算它一个生命周期的适合度。实验分别设计了不同的诱导策略,利用抑制剂去除温度的影响,结果发现他们得到的结果十分吻合Charnov–Bull model。实验证明了,TSD策略对雄性和雌性的生殖成功率有不同的影响,能够使得群体达到最大的适合度。当然了,这是在实验室里面饲养统计的,而且做的也不是鳄鱼(一般学生物的穷鬼也养不起吧~)--来补充一下结果吧,虽然木有什么人关注(灰心~~呜~~)上图,这是上面说的那篇nature的figure1,用Charnov–Bull model拟合Jacky dragon所获得的拟合图。
(外国人貌似对“龙”一点概念都没有)上的研究成果。具体是这么做的:已知该蜥蜴在23~26度、30~33度下能够发育成雌性,而在这之间的温度则发育成雄性。并且该蜥蜴的温度调控机制由一种非醛固酮芳香酶调控,使用该酶的抑制剂能很精确控制蜥蜴的性别分化。由于这种蜥蜴的生活周期一般只有4年(是够短命的啊),他们能够计算它一个生命周期的适合度。实验分别设计了不同的诱导策略,利用抑制剂去除温度的影响,结果发现他们得到的结果十分吻合Charnov–Bull model。实验证明了,TSD策略对雄性和雌性的生殖成功率有不同的影响,能够使得群体达到最大的适合度。当然了,这是在实验室里面饲养统计的,而且做的也不是鳄鱼(一般学生物的穷鬼也养不起吧~)--来补充一下结果吧,虽然木有什么人关注(灰心~~呜~~)上图,这是上面说的那篇nature的figure1,用Charnov–Bull model拟合Jacky dragon所获得的拟合图。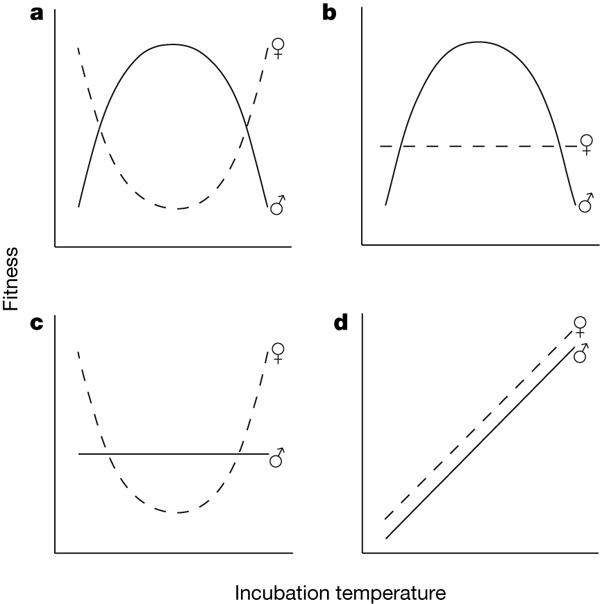 简单的说,横坐标是卵受到的不同的诱导温度,纵坐标是适合度,黑线表示采取子代雄性的适合度,虚线表示雌性的适合度。图a可以看到按照自然的调节情况下(两边温度产生雌性,中间的温度产生雄性)再子代能获得最高的适合度;图b是如果雌性的性别决定不受温度调节,而雄性受温度调节,产生的子代的适合度;图c雄性的性别决定不受温度调节,而雌性受温度调节,产生的子代的适合度;图d是雌性和雄性受对温度调控响应相同。简单的说,横坐标是卵受到的不同的诱导温度,纵坐标是适合度,黑线表示采取子代雄性的适合度,虚线表示雌性的适合度。图a可以看到按照自然的调节情况下(两边温度产生雌性,中间的温度产生雄性)再子代能获得最高的适合度;图b是如果雌性的性别决定不受温度调节,而雄性受温度调节,产生的子代的适合度;图c雄性的性别决定不受温度调节,而雌性受温度调节,产生的子代的适合度;图d是雌性和雄性受对温度调控响应相同。接下来,他们啪啦啪啦~~做了好几年的实验...得到了一下的这张图:
简单的说,横坐标是卵受到的不同的诱导温度,纵坐标是适合度,黑线表示采取子代雄性的适合度,虚线表示雌性的适合度。图a可以看到按照自然的调节情况下(两边温度产生雌性,中间的温度产生雄性)再子代能获得最高的适合度;图b是如果雌性的性别决定不受温度调节,而雄性受温度调节,产生的子代的适合度;图c雄性的性别决定不受温度调节,而雌性受温度调节,产生的子代的适合度;图d是雌性和雄性受对温度调控响应相同。简单的说,横坐标是卵受到的不同的诱导温度,纵坐标是适合度,黑线表示采取子代雄性的适合度,虚线表示雌性的适合度。图a可以看到按照自然的调节情况下(两边温度产生雌性,中间的温度产生雄性)再子代能获得最高的适合度;图b是如果雌性的性别决定不受温度调节,而雄性受温度调节,产生的子代的适合度;图c雄性的性别决定不受温度调节,而雌性受温度调节,产生的子代的适合度;图d是雌性和雄性受对温度调控响应相同。接下来,他们啪啦啪啦~~做了好几年的实验...得到了一下的这张图: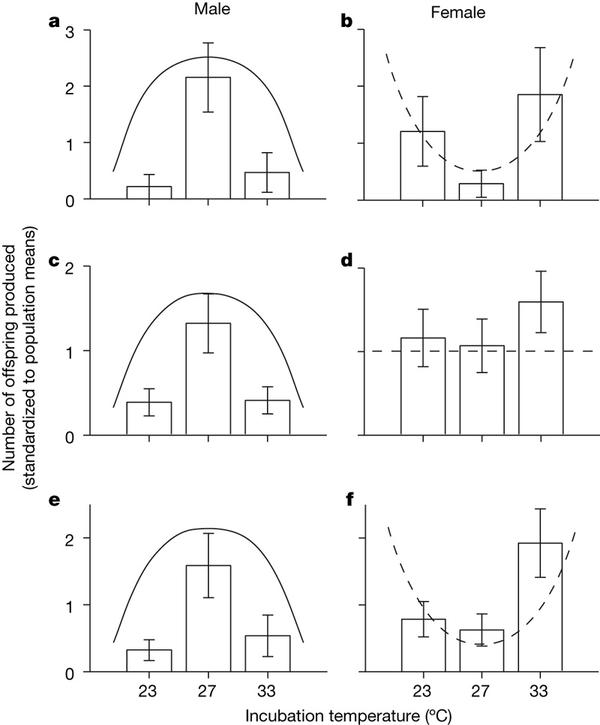 这张图是他们做的从05-06,06-07,已经三年间数据的统计,图表和上图的a很像我就不细说了;结果和模型拟合的数据几乎是完美匹配,证明了不同温度决定性别的策略能够使得后代的适合度最大化。这个模型的建立和验证也十分有意思,有机会再来补充吧~这张图是他们做的从05-06,06-07,已经三年间数据的统计,图表和上图的a很像我就不细说了;结果和模型拟合的数据几乎是完美匹配,证明了不同温度决定性别的策略能够使得后代的适合度最大化。这个模型的建立和验证也十分有意思,有机会再来补充吧~ps:鄙人不是相关领域的,论述有不当处,请大家指正啊~萌萌哒~参考文献:When is sex environmentally determined?Heredity - Abstract of article: Changes in the heterogametic mechanism of sex determination收藏•没有帮助•举报•作者保留权利收起玉山子Biochemistry/Nutriology/NYKnicks/NYRan…收录于 编辑推荐•126 人赞同谢 @袁霖 邀。 鳄鱼及龟类的性别决定方式与鸟类、灵长类等高等动物不同,属于TSD(Temperature-dependent sex determination感谢@严恒斌 指正)温度依赖型。 也即由于一些环境变量(如温度)的改变,激活下游通路的不同反应,对基因的表达进行调控,导致表型…显示全部谢 @袁霖 邀。鳄鱼及龟类的性别决定方式与鸟类、灵长类等高等动物不同,属于TSD(Temperature-dependent sex determination感谢@严恒斌 指正)温度依赖型。也即由于一些环境变量(如温度)的改变,激活下游通路的不同反应,对基因的表达进行调控,导致表型不同。目前关于爬行动物性别决定模式,有多种假说。请参看:温度依赖型性别决定的分子机制这种DNA所携带遗传信息不发生改变,而表型发生变化的问题,有专门的学科称为表观遗传学epigenetics。具体发生改变的机制主要有以下几个方面:1.染色质水平及DNA分子水平上的甲基化、乙酰化修饰DNA的表达极大程度上受到上游顺式作用元件中调控序列,以及下游序列的甲基化修饰程度调控。而DNA分子的甲基化总体上是受到环境影响的。2.RNAi(RNA干扰作用)一些小分子双链RNA(dsRNA)对其互补序列的mRNA具有沉默作用。而这些dsRNA可以是外源性的,也可以是内源性的。3.极端环境下的应急反应如HSF热应激因子诱导HSP热应激蛋白的表达以帮助新生肽在高温下正确折叠等。举一个例子,雌性三花猫的毛色就是由于X染色体中的一条随机失活而导致的。称为剂量补偿效应,高度凝缩失活的X染色体称为巴氏小体,失活的过程称为莱昂化。X染色体上携带有猫的毛色基因,B为黑色毛色,b为橘色毛色,而在生长发育过程中,体细胞中的某一条X染色体发生随机失活,所以毛的颜色是交错而随机的黑橘相间。
这张图是他们做的从05-06,06-07,已经三年间数据的统计,图表和上图的a很像我就不细说了;结果和模型拟合的数据几乎是完美匹配,证明了不同温度决定性别的策略能够使得后代的适合度最大化。这个模型的建立和验证也十分有意思,有机会再来补充吧~这张图是他们做的从05-06,06-07,已经三年间数据的统计,图表和上图的a很像我就不细说了;结果和模型拟合的数据几乎是完美匹配,证明了不同温度决定性别的策略能够使得后代的适合度最大化。这个模型的建立和验证也十分有意思,有机会再来补充吧~ps:鄙人不是相关领域的,论述有不当处,请大家指正啊~萌萌哒~参考文献:When is sex environmentally determined?Heredity - Abstract of article: Changes in the heterogametic mechanism of sex determination收藏•没有帮助•举报•作者保留权利收起玉山子Biochemistry/Nutriology/NYKnicks/NYRan…收录于 编辑推荐•126 人赞同谢 @袁霖 邀。 鳄鱼及龟类的性别决定方式与鸟类、灵长类等高等动物不同,属于TSD(Temperature-dependent sex determination感谢@严恒斌 指正)温度依赖型。 也即由于一些环境变量(如温度)的改变,激活下游通路的不同反应,对基因的表达进行调控,导致表型…显示全部谢 @袁霖 邀。鳄鱼及龟类的性别决定方式与鸟类、灵长类等高等动物不同,属于TSD(Temperature-dependent sex determination感谢@严恒斌 指正)温度依赖型。也即由于一些环境变量(如温度)的改变,激活下游通路的不同反应,对基因的表达进行调控,导致表型不同。目前关于爬行动物性别决定模式,有多种假说。请参看:温度依赖型性别决定的分子机制这种DNA所携带遗传信息不发生改变,而表型发生变化的问题,有专门的学科称为表观遗传学epigenetics。具体发生改变的机制主要有以下几个方面:1.染色质水平及DNA分子水平上的甲基化、乙酰化修饰DNA的表达极大程度上受到上游顺式作用元件中调控序列,以及下游序列的甲基化修饰程度调控。而DNA分子的甲基化总体上是受到环境影响的。2.RNAi(RNA干扰作用)一些小分子双链RNA(dsRNA)对其互补序列的mRNA具有沉默作用。而这些dsRNA可以是外源性的,也可以是内源性的。3.极端环境下的应急反应如HSF热应激因子诱导HSP热应激蛋白的表达以帮助新生肽在高温下正确折叠等。举一个例子,雌性三花猫的毛色就是由于X染色体中的一条随机失活而导致的。称为剂量补偿效应,高度凝缩失活的X染色体称为巴氏小体,失活的过程称为莱昂化。X染色体上携带有猫的毛色基因,B为黑色毛色,b为橘色毛色,而在生长发育过程中,体细胞中的某一条X染色体发生随机失活,所以毛的颜色是交错而随机的黑橘相间。
a href = "javascript:void(0)" onclick="javacrit:window.open('‘);window.open('‘);"
用什么地图。我前天学的。忘了。很好实现的。
科技创新导报2010 NO.18 Technology Innovation Herald 技术创新 基于垂直搜索引擎的旅游线路评价模型的设计 陈高维1 邓天权1,2 曾云磊1 王维国3 张龙1 (1.电子科技大学 四川成都 611731; 2.常州大学 江苏常州 213164; 3.成都登巅科技有限公司 四川成都 610041)摘 要:本文设计了一个基于垂直搜索引擎技术的旅游线路评价推荐模型系统。该系统首先采用垂直搜索引擎技术针对旅游行业网站抓取特定信息,提取旅游路线及相关旅游资讯信息,并辅以人工资讯录入方式,建立旅游路线、旅游资讯数据库。关键词:垂直搜索引擎 信息提取 旅游线路评价模型中图分类号:TP3文献标识码:A文章编号:1674-098X(2010)06(c)-0024-02 1 引言 随着互联网的普及,人们越来越习惯于在出门旅游之前通过互联网了解一些旅游相关的资讯。但是,在浩如烟海的互联网上人们想要获取特定的旅游资讯并不是一件容易的事情。为了满足越来越多游客的旅游资讯搜索需求,帮助游客轻松获取旅游路线信息和旅途上的各类资讯。本课题研究了基于垂直搜索引擎的旅游线路评价推荐系统,为游客提供旅游线路的搜索服务,推荐最优路线,提供旅游路线上相关旅游资讯。 2 垂直搜索引擎 垂直 搜索引擎实现的流程大致如下:spider抓取网页后,对网页中信息进行抽取,然后对上述非结构化数据进行清洗、去重、分类、分析比较、数据挖掘,抽取出结构化的数据储存到数据库中,最后通过中文分词建立索引提供用户搜索。其关键技术有: (1)面向主题的高效蜘蛛程序 主题蜘蛛程序[2]是垂直搜索引擎的重 要组成部分。其抓取范围一般只限于特定的主题或专门的领域。主题蜘蛛的设计通常需要解决好主题相关度的预测、种子站点的选择方案、URL的搜索策略等问题。 (2)网页信息的格式化提取 信息抽取(information Exaction,IE)[3]一般定义为从一段文本中抽取指定的预先想要的信息(事件、事实),表示为结构化的、统一的形式,供信息查询、文本深层挖掘,问答系统、抽样统计等应用.目前比较比较常 [4] 用的方法有:①基于特征模式匹配的信息抽取。②基于归纳学习的信息抽取。③基于网页结构特征分析的信息抽取。④基于on-tology的Web信息抽取。前3几种信息抽取的方法虽各有其特点,但技术上主要是通过为待提取的目标建立相应的模板库,并将文档内容与模板库中的模板匹配而实现提取。模板的表达能力直接影响系统的准确度。第四种方法引入本体(Ontology)的概念较好的解决了词序、多义等问题,本体论从语义信息入手进行抽取。但是对特定领域本体构建是一件非常困难的事情。 3 旅游线路推荐系统的设计与实现 3.1系统的主要功能 为了给游客提供高质量、个性化的旅游资讯服务。本文在旅游信息的获取、提取、存储、展示技术研究的基础上,综合考虑了旅游周期、旅游价格、景区类型、景区动态、交通状况、旅游安全、旅游季节、服务质量等等影响游客旅游体验的因素,设计了旅游路线评价模型。通过该模型可以计算满足游客搜索请求的每一个条旅游路线 图1 的推荐值。为游客推荐最符合其个性化要求的旅游线路。通过图形化技术(MAP)友好的展示旅游线路,同时提供旅途中的餐饮、住宿、交通、景点动态信息等等旅游相关信息。帮助游客在出发前决策旅行线路,并充分了解旅途中的相关信息,以便为旅行做好充分准备。3.2系统总体结构设计 基于垂直搜索引擎的旅游线路推荐系统主要包含以下三大部分:旅游数据采集系统、决策数据生成产系统、旅游线路搜索推荐系统。 (1)数据采集系统数据的采集、格式化存储是本系统的核心之一。数据来源有两种方式:爬虫程序采集、管理端人工录入。主题爬虫在Heri-trix的基础上进行扩展定制,实现面向旅游的主题爬虫程序。由于本系统对数据的准确度要求比较高,因此对一些结构化显示的数据采用模板匹配的方式进行较为准确的抽取。对于一些非结构化的网页数据,信息往往蕴含在长篇的文章中。这类信息首先采用向量模型的方法进行分类过滤,然后采用HTMLParser与正则表达式技术相结合的方法提取主体信息。由人工参与信息的提取与审核。 (2)决策数据生成系统 在数据采集的基础上,将所有的数据进行格式化存储。系统数据分为三个部分:路线数据、路线相关动态信息、其他旅游资讯。将路线数据以XML的格式进行存储,并建立索引,方便路线搜索。路线相关动态信息是进行路线推荐评分的重要依据。其他旅游资讯将做为路线辅助资讯在用户界面上予以显示,增加信息量,提高友好度。 (3)路线搜索评价推荐系统 系统根据用户给出的初始条件(例如:出发城市、目的城市、景区类型、旅游天数、费用预算)在路线索引中进行筛选,获取符合用户要求的旅游路线,并根据路线评价模型进行排序推荐。最后将推荐结果返回到用户的界面上,并从数据库中查询出与路线匹配的旅游资讯信息进行异步展示。3.4旅游线路推荐的动态评分模型设计与验证 3.4.1旅游线路推荐的动态评分模型设计 不同的旅游线路之间的评分是一件比较困难的事情。因为旅行线路有长有短,景点也有不同等级。很多路线往往不具有可 致谢:在此感谢本文研究的资助方:登巅科技netsget文旅数字化项目组的全资支持,和电子科技大学和常州大学DIR研究中心同事们的 共同努力。 24 科技创新导报 Science and Technology Innovation Herald 技术创新 比性。因为很难找到一个通用的可以量化的计算方法对差异化的旅游线路进行公平的评价。因此本系统将在路线相当的情况下对旅行线路进行评价。所谓路线相当在此理解为旅游费用相当、旅游时间相当。 游客们对旅游线路的评价多来自于游客自己的亲身体验。我们可以从游客体验的角度来设计旅游线路动态评价模型。所谓动态,就是由该模型计算出来的推荐值应该随着影响游客体验的事情的发生而发生变化。 3.4.1.1动态评分模型设计需满足的要求 (1)对同一旅游线路在不同时期的推荐值,应该随影响因素的变化而变化。(2)能够考虑到不同路线的实际差异性,要做到灵活、通用。(3)对不同的路线进行评价应该考虑到公平性。 旅游线路推荐会受到一定因素的影响,我们进行仔细分析,得出影响因子分为以下两种类型: (1)决定性因子F(影响到景区旅游的可行度)如:道路故障、卫生安全(传染病)、自然灾害(山洪)、景点整修等不可预料的其它情况。(2)非决定性因子f(影响景区的完美度)如:天气因数、服务质量。 3.4.1.2动态评分模型的设计 对一条旅游路线的评价,分为两个步骤。 第一步,对路线中所有的节点进行评价,计算景点的当前推荐值。第二步,综合路线中所有景点进行评价,对路线进行综合评价。 动态评分模型是本系统的 核心部分,其结构如图1。 风景点的推荐值计算公式为: 2010 NO.18 Science and Technology Innov科技创新导报 g:风景区的等级 fj:的取值范围0~1,最好状态下 Fi、 值为1,最差状态下值为0 r的值越大 推荐度越高,值越小推荐 度越低。等于0时表示此线路不可行。 线路推荐值计算方法 : 假设线路上有n个景点, ri表示第i个景点 mi表示景点间线路因子,表示路线的推荐值。 的通畅程度。M表示整条路线的通畅因子。 M (2) 则线路的推荐 R (3) r=g f i m (1) F:第i个决定性因子的状态值;j:第j个非决定性因子的当前状态值 n:决定性因子的个数; m:非决定性因子的个数; 公式(3)综合考虑了景点质量、决定性影响因子、非决定性影响因子、线路通畅因子等等因素。通过公式(3)可以计算出每个可能的路径(线路库中线路、游客自定义线路)的推荐值。给出旅游路线当前推荐排名,同时也可以十分容易的分析得出影响推荐值的景区及因子,让游客知道评分的客观依据。 3.4.2旅游线路推荐的动态评分模型的测试 旅游路线推荐公式综合考量了景点质量、决定性影响因子、非决定性影响因子等因素。我们设置了几组数据,来模拟测试一下结果。 F3卫生 F2景区交通、设: F1景点状态、 f2星期因 f1季节因素、 F4自然灾害、安全、 f3服务因素素、 计算结果为: r1={3.98、2.21、2.39} R1=2.76 r2={2.24、2.21、2.39} R2=2.28 r3={3.98、3.31、2.39} R3=2.99 r4={0、2.08、2.39} R4=0测试一个关键因素变化的影响: R1=2.76 R2=2.28 测试一个非关键因素变化的影响: R1=2.76 R3=2.99测试一个关键因素、非关键因素为0的影响: 表1测试数据1 R1=2.76 R4=0 通过模拟测试我们发现,我们发现公式(3)具有以下特性: (1)关键因子的浮动对线路推荐值的影响比较大。(2)非关键因子的变化对线路推荐值的影响相对较小。(3)当某一关键因子出现严重问题时(值为0)对线路的推荐影响是致命的,某一非关键因子出现严重问题时(值为0)不会对线路推荐值造成致命的影响。(4)由于F的可扩展性,系统比较灵活,能够较好的包容不同旅行的差异性。(5)本公式是在旅游天数、旅游费用相近(路线的可比性比较强)的前提条件下进行的评比,还是能较好的体现公平性的。 综上所述,经过试验分析说明公式(2)完全满足我们设置旅游路线推荐评分公式的3个基本条件。 4 结语 本文介绍的基于垂直搜索引擎的旅游线路推荐系统,有两个主要特色,一是能根据旅客的初始要求搜索满足要求的旅行线路,并能根据线路推荐模型计算推荐值,将推荐度高的旅行线路展示在用户面前;二是系统可以在地图上形象的展示与每条旅行线路相关的所有常见的旅游资讯。 本系统在旅行线路推荐的基础上,通过旅游线路将相关的旅游资讯关联起来,游客通过本系统可以十分便捷的获取想要的旅游信息。在节省信息搜索时间的同时,大大提升了信息搜索的服务体验。 参考文献 [1]肖冬梅.垂直搜索引擎研究[J].图书馆 学研究,2003(2):87. [2]李盛韬.主题WEB信息采集的研究与设 计[M].北京:清华大学出版社,2003:488~494. [3]王春龙.基于网站语义结构的信息抽取 系统的研究与实现[D].北京交通大学硕士学位论文. [4]贺令 亚 , 柳 佳 刚 . 基 于 Web 的 包 装器技 术的现状与 发 展 [J]. 电 脑 开 发 与 应 用 , 1003 —5850(2007)06—0027—03. 表2测试数据2 科技创新导报 Science and Technology Innovation Herald25
python网络爬虫毕业论文
根据题目描述,"基于python的知识问答社区网络爬虫系统的设计与实现",可以理解为设计并实现一个能够爬取知识问答社区网站上的数据的网络爬虫系统,使用Python编程语言进行开发。此系统的目的是通过自动化地收集数据来分析知识问答社区中的问题和回答,可能会涉及到使用Python的相关库和框架来构建网络爬虫,编写数据处理和分析代码,以及构建用户界面等功能。需要注意的是,在爬取网站数据时,需要尊重网站的规则和政策,避免对网站造成不良影响或侵犯用户隐私等问题。同时,也需要考虑到网络爬虫的性能、稳定性和可扩展性等方面的问题,以确保系统能够在长期运行中稳定可靠地工作。
题目指的是设计和实现一个基于Python的知识问答社区网络爬虫系统,该系统可以从网络上抓取知识问答社区的数据,并将其转换成可以用于分析的格式。
网络爬虫硕士毕业论文
计算机网络技术专业毕业论文题目
你是不是在为选计算机网络技术专业毕业论文题目烦恼呢?以下是我为大家整理的关于计算机网络技术专业毕业论文题目,希望大家喜欢!
1. 基于移动互联网下服装品牌的推广及应用研究
2. 基于Spark平台的恶意流量监测分析系统
3. 基于MOOC翻转课堂教学模式的设计与应用研究
4. 一种数字货币系统P2P消息传输机制的设计与实现
5. 基于OpenStack开放云管理平台研究
6. 基于OpenFlow的软件定义网络路由技术研究
7. 未来互联网试验平台若干关键技术研究
8. 基于云计算的海量网络流量数据分析处理及关键算法研究
9. 基于网络化数据分析的社会计算关键问题研究
10. 基于Hadoop的网络流量分析系统的研究与应用
11. 基于支持向量机的移动互联网用户行为偏好研究
12. “网络技术应用”微课程设计与建设
13. 移动互联网环境下用户隐私关注的影响因素及隐私信息扩散规律研究
14. 未来互联网络资源负载均衡研究
15. 面向云数据中心的虚拟机调度机制研究
16. 基于OpenFlow的数据中心网络路由策略研究
17. 云计算环境下资源需求预测与优化配置方法研究
18. 基于多维属性的社会网络信息传播模型研究
19. 基于遗传算法的云计算任务调度算法研究
20. 基于OpenStack开源云平台的网络模型研究
21. SDN控制架构及应用开发的研究和设计
22. 云环境下的资源调度算法研究
23. 异构网络环境下多径并行传输若干关键技术研究
24. OpenFlow网络中QoS管理系统的研究与实现
25. 云协助文件共享与发布系统优化策略研究
26. 大规模数据中心可扩展交换与网络拓扑结构研究
27. 数据中心网络节能路由研究
28. Hadoop集群监控系统的设计与实现
29. 网络虚拟化映射算法研究
30. 软件定义网络分布式控制平台的研究与实现
31. 网络虚拟化资源管理及虚拟网络应用研究
32. 基于流聚类的网络业务识别关键技术研究
33. 基于自适应流抽样测量的网络异常检测技术研究
34. 未来网络虚拟化资源管理机制研究
35. 大规模社会网络中影响最大化问题高效处理技术研究
36. 数据中心网络的流量管理和优化问题研究
37. 云计算环境下基于虚拟网络的资源分配技术研究
38. 基于用户行为分析的精确营销系统设计与实现
39. P2P网络中基于博弈算法的优化技术研究
40. 基于灰色神经网络模型的网络流量预测算法研究
41. 基于KNN算法的Android应用异常检测技术研究
42. 基于macvlan的Docker容器网络系统的设计与实现
43. 基于容器云平台的网络资源管理与配置系统设计与实现
44. 基于OpenStack的SDN仿真网络的研究
45. 一个基于云平台的智慧校园数据中心的设计与实现
46. 基于SDN的数据中心网络流量调度与负载均衡研究
47. 软件定义网络(SDN)网络管理关键技术研究
48. 基于SDN的数据中心网络动态负载均衡研究
49. 基于移动智能终端的医疗服务系统设计与实现
50. 基于SDN的网络流量控制模型设计与研究
51. 《计算机网络》课程移动学习网站的设计与开发
52. 数据挖掘技术在网络教学中的应用研究
53. 移动互联网即时通讯产品的用户体验要素研究
54. 基于SDN的负载均衡节能技术研究
55. 基于SDN和OpenFlow的流量分析系统的研究与设计
56. 基于SDN的网络资源虚拟化的研究与设计
57. SDN中面向北向的`控制器关键技术的研究
58. 基于SDN的网络流量工程研究
59. 基于博弈论的云计算资源调度方法研究
60. 基于Hadoop的分布式网络爬虫系统的研究与实现
61. 一种基于SDN的IP骨干网流量调度方案的研究与实现
62. 基于软件定义网络的WLAN中DDoS攻击检测和防护
63. 基于SDN的集群控制器负载均衡的研究
64. 基于大数据的网络用户行为分析
65. 基于机器学习的P2P网络流分类研究
66. 移动互联网用户生成内容动机分析与质量评价研究
67. 基于大数据的网络恶意流量分析系统的设计与实现
68. 面向SDN的流量调度技术研究
69. 基于P2P的小额借贷融资平台的设计与实现
70. 基于移动互联网的智慧校园应用研究
71. 内容中心网络建模与内容放置问题研究
72. 分布式移动性管理架构下的资源优化机制研究
73. 基于模糊综合评价的P2P网络流量优化方法研究
74. 面向新型互联网架构的移动性管理关键技术研究
75. 虚拟网络映射策略与算法研究
76. 互联网流量特征智能提取关键技术研究
77. 云环境下基于随机优化的动态资源调度研究
78. OpenFlow网络中虚拟化机制的研究与实现
79. 基于时间相关的网络流量建模与预测研究
80. B2C电子商务物流网络优化技术的研究与实现
81. 基于SDN的信息网络的设计与实现
82. 基于网络编码的数据通信技术研究
83. 计算机网络可靠性分析与设计
84. 基于OpenFlow的分布式网络中负载均衡路由的研究
85. 城市电子商务物流网络优化设计与系统实现
86. 基于分形的网络流量分析及异常检测技术研究
87. 网络虚拟化环境下的网络资源分配与故障诊断技术
88. 基于中国互联网的P2P-VoIP系统网络域若干关键技术研究
89. 网络流量模型化与拥塞控制研究
90. 计算机网络脆弱性评估方法研究
91. Hadoop云平台下调度算法的研究
92. 网络虚拟化环境下资源管理关键技术研究
93. 高性能网络虚拟化技术研究
94. 互联网流量识别技术研究
95. 虚拟网络映射机制与算法研究
96. 基于业务体验的无线资源管理策略研究
97. 移动互联网络安全认证及安全应用中若干关键技术研究
98. 基于DHT的分布式网络中负载均衡机制及其安全性的研究
99. 高速复杂网络环境下异常流量检测技术研究
100. 基于移动互联网技术的移动图书馆系统研建
101. 基于连接度量的社区发现研究
102. 面向可信计算的分布式故障检测系统研究
103. 社会化媒体内容关注度分析与建模方法研究
104. P2P资源共享系统中的资源定位研究
105. 基于Flash的三维WebGIS可视化研究
106. P2P应用中的用户行为与系统性能研究
107. 基于MongoDB的云监控设计与应用
108. 基于流量监测的网络用户行为分析
109. 移动社交网络平台的研究与实现
110. 基于 Android 系统的 Camera 模块设计和实现
111. 基于Android定制的Lephone系统设计与实现
112. 云计算环境下资源负载均衡调度算法研究
113. 集群负载均衡关键技术研究
114. 云环境下作业调度算法研究与实现
115. 移动互联网终端界面设计研究
116. 云计算中的网络拓扑设计和Hadoop平台研究
117. pc集群作业调度算法研究
118. 内容中心网络网内缓存策略研究
119. 内容中心网络的路由转发机制研究
120. 学习分析技术在网络课程学习中的应用实践研究
做爬虫,特别是python写说容易挺容易,说难也挺难的,举个栗子 简单的:将上面的所有代码爬下来写个for循环,调用urllib2的几个函数就成了,基本10行到20行以内的代码难度0情景:1.网站服务器很卡,有些页面打不开,urlopen直接就无限卡死在了某些页面上(2.6以后urlopen有了timeout)2.爬下来的网站出现乱码,你得分析网页的编码3.网页用了gzip压缩,你是要在header里面约定好默认不压缩还是页面下载完毕后自己解压4.你的爬虫太快了,被服务器要求停下来喝口茶5.服务器不喜欢被爬虫爬,会对对header头部浏览器信息进行分析,如何伪造6.爬虫整体的设计,用bfs爬还是dfs爬7.如何用有效的数据结构储存url使得爬过的页面不被重复爬到8.比如1024之类的网站(逃,你得登录后才能爬到它的内容,如何获取cookies以上问题都是写爬虫很常见的,由于python强大的库,略微加了一些代码而已难度1情景:1.还是cookies问题,网站肯定会有一个地方是log out,爬虫爬的过程中怎样避免爬到各种Log out导致session失效2.如果有验证码才能爬到的地方,如何绕开或者识别验证码3.嫌速度太慢,开50个线程一起爬网站数据难度2情景:1.对于复杂的页面,如何有效的提取它的链接,需要对正则表达式非常熟练2.有些标签是用Js动态生成的,js本身可以是加密的,甚至奇葩一点是jsfuck,如何爬到这些难度3总之爬虫最重要的还是模拟浏览器的行为,具体程序有多复杂,由你想实现的功能和被爬的网站本身所决定爬虫写得不多,暂时能想到的就这么多,欢迎补充
摘 要网络中的资源非常丰富,但是如何有效的搜索信息却是一件困难的事情。建立搜索引擎就是解决这个问题的最好方法。本论文首先详细介绍了基于英特网的搜索引擎的系统结构,然后从网络机器人、索引引擎、Web服务器三个方面进行详细的说明。为了更加深刻的理解这种技术,本人还亲自实现了一个自己的Java搜索引擎——新闻搜索引擎。新闻搜索引擎是从指定的Web页面中按照超连接进行解析、搜索,并把搜索到的每条新闻进行索引后加入数据库。然后通过Web服务器接受客户端请求后从索引数据库中搜索出所匹配的新闻。本人在介绍搜索引擎的章节中除了详细的阐述技术核心外还结合了新闻搜索引擎的实现代码来说明,图文并茂、易于理解。 关键字:搜索引擎,网络机器人,Lucene,中文分词,JavaCC AbstractThe resources in the internet are abundant, but it is a difficult job to search some useful information. So a search engine is the best method to solve this problem. This article fist introduces the system structure of search engine based on the internet in detail, and then gives a minute explanation form Spider search, engine and web server. In order to understand the technology more deeply, I have programmed a news search engine by myself in Java.The news search engine is explained and searched according to hyperlink from a appointed web page, then indexes every searched information and adds it to the index database. Then after receiving the customers' requests from the web server, it soon searches the right news form the index engine,In the chapter of introducing search engine, it is not only elaborating the core technology, but also combine with the modern code, pictures included, easy to understand. Key Words:Search Engine, Spider, Lucene, Phrase Query, JavaCC 目 录第1章 引言··· 11.1 选题背景:··· 11.2 现实意义··· 1第2章 搜索引擎的结构··· 32.1 系统概述··· 32.2 搜索引擎的构成··· 32.2.1 网络机器人··· 32.2.2 索引与搜索··· 32.2.3 Web服务器··· 32.3 搜索引擎的主要指标及分析··· 42.4 小节··· 4第3章 网络机器人··· 53.1 什么是网络机器人··· 53.2 网络机器人的结构分析··· 53.2.1 如何解析HTML· 53.2.2 该类几种重要的方法。··· 63.2.3 Spider程序结构··· 63.2.4 如何构造Spider程序··· 73.2.5 如何提高程序性能··· 83.2.6 网络机器人的代码分析··· 93.3 小节··· 10第4章 基于Lucene的索引与搜索··· 114.1 什么是全文检索与全文检索系统?··· 114.2 什么是Lucene全文检索··· 124.3 Lucene的系统结构分析··· 134.3.1 系统结构组织··· 134.3.2 数据流分析··· 144.4 Lucene索引构建逻辑模块分析··· 154.4.1 绪论··· 154.4.2 对象体系与UML图··· 164.4.3 Lucene的包结构··· 204.4.4 Lucene的主要逻辑图··· 214.4.5 对Lucene包的小结··· 224.5 Lucene查询逻辑··· 224.5.1 查询者输入查询条件··· 224.5.2 查询条件被传达到查询分析器中··· 224.5.3 查询遍历树··· 234.5.4 返回结果··· 234.6 Lucene 检索原理··· 234.7 Lucene和Nucth的中文分析模块··· 254.7.1 Nutch分析··· 254.7.2 Nutch中文搜索3.1 中文分词··· 264.7.3 利用JavaCC构造中文分析模块··· 274.7.4 分词小结··· 284.8 Lucene与Spider的结合··· 284.8.1 Index类的实现··· 284.8.2 HTML解析类··· 294.9 Lucene 小结··· 31第5章 基于Lucene的搜索引擎实现··· 325.1 基于Tomcat的Web服务器··· 325.1.1 什么是基于Tomcat的Web服务器··· 325.2 用户接口设计··· 325.2.1 客户端设计··· 325.2.2 服务端设计··· 335.3 在Tomcat上部署项目··· 355.4 小节··· 35第6章 搜索引擎策略··· 366.1 简介··· 366.2 面向主题的搜索策略··· 366.2.1 导向词··· 366.2.2 网页评级··· 366.2.3 权威网页和中心网页··· 376.3 小节··· 38结束语··· 39参考文献··· 40致 谢··· 41外文资料原文··· 42外文原文翻译··· 48 第1章 引言1.1 选题背景:面对浩瀚的网络资源,搜索引擎为所有网上冲浪的用户提供了一个入口,毫不夸张的说,所有的用户都可以从搜索出发到达自己想去的网上任何一个地方。因此它也成为除了电子邮件以外最多人使用的网上服务。搜索引擎技术伴随着WWW的发展是引人注目的。搜索引擎大约经历了三代的更新发展:第一代搜索引擎出现于1994年。这类搜索引擎一般都索引少于1,000,000个网页,极少重新搜集网页并去刷新索引。而且其检索速度非常慢,一般都要等待10秒甚至更长的时间。在实现技术上也基本沿用较为成熟的IR(Information Retrieval)、网络、数据库等技术,相当于利用一些已有技术实现的一个WWW上的应用。在1994年3月到4月,网络爬虫World Web Worm (WWWW)平均每天承受大约1500次查询。大约在1996年出现的第二代搜索引擎系统大多采用分布式方案(多个微型计算机协同工作)来提高数据规模、响应速度和用户数量,它们一般都保持一个大约50,000,000网页的索引数据库,每天能够响应10,000,000次用户检索请求。1997年11月,当时最先进的几个搜索引擎号称能建立从2,000,000到100,000,000的网页索引。Altavista搜索引擎声称他们每天大概要承受20,000,000次查询。结束语本课题对基于因特网的Java搜索引擎结构和性能指标进行了分析,了解Spider程序的结构和功能。在进行海量数据搜索时,如果使用单纯的数据库技术,那将是非常痛苦的,速度将是极大的瓶颈。所以本文提出了使用全文搜索引擎Lucene进行索引、搜索。解决中文分词和有效的中文搜索信息。同时解决了如何把Lucene全文搜索引擎和Spider程序互相集合来实现新闻搜索的功能。对于如何构架基于Tomcat的Web服务器,使得用户通过浏览器进行新闻的搜索有了一定的理解,对Tomcat如何部署进行了说明。在些基础上,终于可以调试出一个简单的在本地搜索新闻Java搜索引擎。参考文献[1] Jeff Heaton(美), Programming Spiders, Bots, and Aggregator in Java.[2] Borland Software Corporation(美),JBuilder培训教程(译者:周鹏 [等] 译)北京:机械工业出版社[3]徐宝文,张卫丰. 搜索引擎与信息获取技术.北京:清华大学出版社,2003.5[4]车东.基于Java的全文搜索引擎Lucene[5]罗旭.主题搜索引擎的设计与实现[6]Bruce Eckel(美).Thinking in Java.北京:机械工业出版社[7] Otis Gospodnetic Erik Hatcher (美).Action in Lucene.电子工业出版社,2007.1[8]耿祥义,张跃平. JAVA2实用教程(第二版).北京:清华大学出版社,2004.2[9]刘彬.JSP数据库高级教程.北京:清华大学出版社,2006.3[10]刘卫国,严晖.数据库技术与应用——SQL Server.北京:清华大学出版社,2007.1[11]闫宏飞.Tiny Search Engine: Design and implementation(PPT). Oct.2003[12]李晓明,闫宏飞,王继民.搜索引擎——原理、技术与系统.北京:科学出版社,2004 更多参考请点击